
Tackle tedious text tasks with timesaving techniques
The next time you get cross-eyed with repetitive text processing, do a little research into RegEx.
RegEx, or regular expressions, is a syntax for describing text patterns. By describing text patterns, you can expand what Find/Change can do for you. RegEx is available in many applications, including FrameMaker, RoboHelp, and Dreamweaver.
Last week I was working with a client who’s “inherited” about 100 help topics, each consisting of a 2-column table used to control the layout. She needed to break the content out of the html tables, but to do so manually was (conservatively) about 50 hours of work.
Using a few internet resources, and a little deductive reasoning, I managed to unwrap the tables in a few hours, rather than a few weeks. By leaving the Replace field blank, I used the following RegEx string to unwrap the table, col, td, and tr elements in her topics:
</?table([^>]*)>
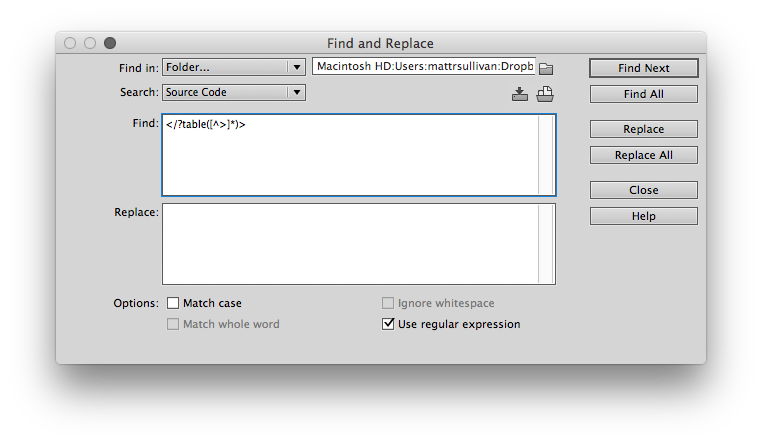 While it looks like gobbledegook on the surface, the string searches for a < followed by an optional / followed by table and anything else (attributes) through to the closing >
While it looks like gobbledegook on the surface, the string searches for a < followed by an optional / followed by table and anything else (attributes) through to the closing >
All in all I removed about 10,000 pairs of tags using 4 Find/Change searches!
UPDATE: 2 minor points…
- The parentheses in the original regex don’t hurt anything, but are only needed if further processing were to be done on the parenthetical portion (and in this case, there’s no further processing)
- My pal, Scott Prentice of Leximation, pointed out that I could’ve done the work in one pass using this modified string:
</?(table|col|tr|td)[^>]*>
That’s ok, it would’ve taken me longer to figure out the single string than it did to run 4x Find/Changes.
50 hours of work, distilled to an afternoon of research and puzzle solving…well worth the effort, even if I do owe a few pals a drink or two for doing some parallel investigation using PERL and XSLT.
Thanks also to Alan Houser, Group Wellesley for pointing out how HTML Tidy could help me process non-conforming code for XSLT processing.
Here are a few resources that can help you get started using RegEx for your own work.
Adobe regex tutorial, Part 1 (includes link to Part 2)
(what led me to my own solution)
Stackflow.com post on selecting tags with RegEx
Peter Grainge’s general post on RegEx
Happy (text string) hunting!

Join over 4,300 of your peers and get my latest content sent to you for free, along with some of my all-time favorites.